YARN Architecture
The fundamental idea of YARN is to split up the functionalities of resource management and job scheduling/monitoring into separate daemons. The idea is to have a global ResourceManager (RM) and per-application ApplicationMaster (AM). An application is either a single job or a DAG of jobs.
The ResourceManager and the NodeManager form the data-computation framework. The ResourceManager is the ultimate authority that arbitrates resources among all the applications in the system. The NodeManager is the per-machine framework agent who is responsible for containers, monitoring their resource usage (cpu, memory, disk, network) and reporting the same to the ResourceManager/Scheduler.
The per-application ApplicationMaster is, in effect, a framework specific library and is tasked with negotiating resources from the ResourceManager and working with the NodeManager(s) to execute and monitor the tasks.

The ResourceManager has two main components: Scheduler and ApplicationsManager.
The Scheduler is responsible for allocating resources to the various running applications subject to familiar constraints of capacities, queues etc. The Scheduler is pure scheduler in the sense that it performs no monitoring or tracking of status for the application. Also, it offers no guarantees about restarting failed tasks either due to application failure or hardware failures. The Scheduler performs its scheduling function based the resource requirements of the applications; it does so based on the abstract notion of a resource Container which incorporates elements such as memory, cpu, disk, network etc.
The Scheduler has a pluggable policy which is responsible for partitioning the cluster resources among the various queues, applications etc. The current schedulers such as the CapacityScheduler and the FairScheduler would be some examples of plug-ins.
The ApplicationsManager is responsible for accepting job-submissions, negotiating the first container for executing the application specific ApplicationMaster and provides the service for restarting the ApplicationMaster container on failure. The per-application ApplicationMaster has the responsibility of negotiating appropriate resource containers from the Scheduler, tracking their status and monitoring for progress.
MapReduce in hadoop-2.x maintains API compatibility with previous stable release (hadoop-1.x). This means that all MapReduce jobs should still run unchanged on top of YARN with just a recompile.
Capacity Scheduler
Purpose
This document describes the CapacityScheduler, a pluggable scheduler for Hadoop which allows for multiple-tenants to securely share a large cluster such that their applications are allocated resources in a timely manner under constraints of allocated capacities.
Overview
The CapacityScheduler is designed to run Hadoop applications as a shared, multi-tenant cluster in an operator-friendly manner while maximizing the throughput and the utilization of the cluster.
Traditionally each organization has it own private set of compute resources that have sufficient capacity to meet the organization’s SLA under peak or near peak conditions. This generally leads to poor average utilization and overhead of managing multiple independent clusters, one per each organization. Sharing clusters between organizations is a cost-effective manner of running large Hadoop installations since this allows them to reap benefits of economies of scale without creating private clusters. However, organizations are concerned about sharing a cluster because they are worried about others using the resources that are critical for their SLAs.
The CapacityScheduler is designed to allow sharing a large cluster while giving each organization capacity guarantees. The central idea is that the available resources in the Hadoop cluster are shared among multiple organizations who collectively fund the cluster based on their computing needs. There is an added benefit that an organization can access any excess capacity not being used by others. This provides elasticity for the organizations in a cost-effective manner.
Sharing clusters across organizations necessitates strong support for multi-tenancy since each organization must be guaranteed capacity and safe-guards to ensure the shared cluster is impervious to single rouge application or user or sets thereof. The CapacityScheduler provides a stringent set of limits to ensure that a single application or user or queue cannot consume disproportionate amount of resources in the cluster. Also, the CapacityScheduler provides limits on initialized/pending applications from a single user and queue to ensure fairness and stability of the cluster.
The primary abstraction provided by the CapacityScheduler is the concept of queues. These queues are typically setup by administrators to reflect the economics of the shared cluster.
To provide further control and predictability on sharing of resources, the CapacityScheduler supports hierarchical queues to ensure resources are shared among the sub-queues of an organization before other queues are allowed to use free resources, there-by providing affinity for sharing free resources among applications of a given organization.
Features
The CapacityScheduler supports the following features:
- Hierarchical Queues – Hierarchy of queues is supported to ensure resources are shared among the sub-queues of an organization before other queues are allowed to use free resources, there-by providing more control and predictability.
- Capacity Guarantees – Queues are allocated a fraction of the capacity of the grid in the sense that a certain capacity of resources will be at their disposal. All applications submitted to a queue will have access to the capacity allocated to the queue. Adminstrators can configure soft limits and optional hard limits on the capacity allocated to each queue.
- Security – Each queue has strict ACLs which controls which users can submit applications to individual queues. Also, there are safe-guards to ensure that users cannot view and/or modify applications from other users. Also, per-queue and system administrator roles are supported.
- Elasticity – Free resources can be allocated to any queue beyond it’s capacity. When there is demand for these resources from queues running below capacity at a future point in time, as tasks scheduled on these resources complete, they will be assigned to applications on queues running below the capacity (pre-emption is not supported). This ensures that resources are available in a predictable and elastic manner to queues, thus preventing artifical silos of resources in the cluster which helps utilization.
- Multi-tenancy – Comprehensive set of limits are provided to prevent a single application, user and queue from monopolizing resources of the queue or the cluster as a whole to ensure that the cluster isn’t overwhelmed.
- Operability
- Runtime Configuration – The queue definitions and properties such as capacity, ACLs can be changed, at runtime, by administrators in a secure manner to minimize disruption to users. Also, a console is provided for users and administrators to view current allocation of resources to various queues in the system. Administrators can add additional queues at runtime, but queues cannot be deleted at runtime.
- Drain applications – Administrators can stop queues at runtime to ensure that while existing applications run to completion, no new applications can be submitted. If a queue is in STOPPED state, new applications cannot be submitted to itself or any of its child queueus. Existing applications continue to completion, thus the queue can be drained gracefully. Administrators can also start the stopped queues.
- Resource-based Scheduling – Support for resource-intensive applications, where-in a application can optionally specify higher resource-requirements than the default, there-by accomodating applications with differing resource requirements. Currently, memory is the the resource requirement supported.
- Queue Mapping based on User or Group – This feature allows users to map a job to a specific queue based on the user or group.
Fair Scheduler
Purpose
This document describes the FairScheduler, a pluggable scheduler for Hadoop that allows YARN applications to share resources in large clusters fairly.
Introduction
Fair scheduling is a method of assigning resources to applications such that all apps get, on average, an equal share of resources over time. Hadoop NextGen is capable of scheduling multiple resource types. By default, the Fair Scheduler bases scheduling fairness decisions only on memory. It can be configured to schedule with both memory and CPU, using the notion of Dominant Resource Fairness developed by Ghodsi et al. When there is a single app running, that app uses the entire cluster. When other apps are submitted, resources that free up are assigned to the new apps, so that each app eventually on gets roughly the same amount of resources. Unlike the default Hadoop scheduler, which forms a queue of apps, this lets short apps finish in reasonable time while not starving long-lived apps. It is also a reasonable way to share a cluster between a number of users. Finally, fair sharing can also work with app priorities – the priorities are used as weights to determine the fraction of total resources that each app should get.
The scheduler organizes apps further into “queues”, and shares resources fairly between these queues. By default, all users share a single queue, named “default”. If an app specifically lists a queue in a container resource request, the request is submitted to that queue. It is also possible to assign queues based on the user name included with the request through configuration. Within each queue, a scheduling policy is used to share resources between the running apps. The default is memory-based fair sharing, but FIFO and multi-resource with Dominant Resource Fairness can also be configured. Queues can be arranged in a hierarchy to divide resources and configured with weights to share the cluster in specific proportions.
In addition to providing fair sharing, the Fair Scheduler allows assigning guaranteed minimum shares to queues, which is useful for ensuring that certain users, groups or production applications always get sufficient resources. When a queue contains apps, it gets at least its minimum share, but when the queue does not need its full guaranteed share, the excess is split between other running apps. This lets the scheduler guarantee capacity for queues while utilizing resources efficiently when these queues don’t contain applications.
The Fair Scheduler lets all apps run by default, but it is also possible to limit the number of running apps per user and per queue through the config file. This can be useful when a user must submit hundreds of apps at once, or in general to improve performance if running too many apps at once would cause too much intermediate data to be created or too much context-switching. Limiting the apps does not cause any subsequently submitted apps to fail, only to wait in the scheduler’s queue until some of the user’s earlier apps finish.
Hierarchical queues with pluggable policies
The fair scheduler supports hierarchical queues. All queues descend from a queue named “root”. Available resources are distributed among the children of the root queue in the typical fair scheduling fashion. Then, the children distribute the resources assigned to them to their children in the same fashion. Applications may only be scheduled on leaf queues. Queues can be specified as children of other queues by placing them as sub-elements of their parents in the fair scheduler allocation file.
A queue’s name starts with the names of its parents, with periods as separators. So a queue named “queue1” under the root queue, would be referred to as “root.queue1”, and a queue named “queue2” under a queue named “parent1” would be referred to as “root.parent1.queue2”. When referring to queues, the root part of the name is optional, so queue1 could be referred to as just “queue1”, and a queue2 could be referred to as just “parent1.queue2”.
Additionally, the fair scheduler allows setting a different custom policy for each queue to allow sharing the queue’s resources in any which way the user wants. A custom policy can be built by extending org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.SchedulingPolicy. FifoPolicy, FairSharePolicy (default), and DominantResourceFairnessPolicy are built-in and can be readily used.
Certain add-ons are not yet supported which existed in the original (MR1) Fair Scheduler. Among them, is the use of a custom policies governing priority “boosting” over certain apps.
Automatically placing applications in queues
The Fair Scheduler allows administrators to configure policies that automatically place submitted applications into appropriate queues. Placement can depend on the user and groups of the submitter and the requested queue passed by the application. A policy consists of a set of rules that are applied sequentially to classify an incoming application. Each rule either places the app into a queue, rejects it, or continues on to the next rule. Refer to the allocation file format below for how to configure these policies.
ResourceManger Restart
Overview
ResourceManager is the central authority that manages resources and schedules applications running atop of YARN. Hence, it is potentially a single point of failure in a Apache YARN cluster. ` This document gives an overview of ResourceManager Restart, a feature that enhances ResourceManager to keep functioning across restarts and also makes ResourceManager down-time invisible to end-users.
ResourceManager Restart feature is divided into two phases:
- ResourceManager Restart Phase 1 (Non-work-preserving RM restart): Enhance RM to persist application/attempt state and other credentials information in a pluggable state-store. RM will reload this information from state-store upon restart and re-kick the previously running applications. Users are not required to re-submit the applications.
- ResourceManager Restart Phase 2 (Work-preserving RM restart): Focus on re-constructing the running state of ResourceManager by combining the container statuses from NodeManagers and container requests from ApplicationMasters upon restart. The key difference from phase 1 is that previously running applications will not be killed after RM restarts, and so applications won’t lose its work because of RM outage.
Feature
- Phase 1: Non-work-preserving RM restart
As of Hadoop 2.4.0 release, only ResourceManager Restart Phase 1 is implemented which is described below.
The overall concept is that RM will persist the application metadata (i.e. ApplicationSubmissionContext) in a pluggable state-store when client submits an application and also saves the final status of the application such as the completion state (failed, killed, finished) and diagnostics when the application completes. Besides, RM also saves the credentials like security keys, tokens to work in a secure environment. Any time RM shuts down, as long as the required information (i.e.application metadata and the alongside credentials if running in a secure environment) is available in the state-store, when RM restarts, it can pick up the application metadata from the state-store and re-submit the application. RM won’t re-submit the applications if they were already completed (i.e. failed, killed, finished) before RM went down.
NodeManagers and clients during the down-time of RM will keep polling RM until RM comes up. When RM becomes alive, it will send a re-sync command to all the NodeManagers and ApplicationMasters it was talking to via heartbeats. As of Hadoop 2.4.0 release, the behaviors for NodeManagers and ApplicationMasters to handle this command are: NMs will kill all its managed containers and re-register with RM. From the RM’s perspective, these re-registered NodeManagers are similar to the newly joining NMs. AMs(e.g. MapReduce AM) are expected to shutdown when they receive the re-sync command. After RM restarts and loads all the application metadata, credentials from state-store and populates them into memory, it will create a new attempt (i.e. ApplicationMaster) for each application that was not yet completed and re-kick that application as usual. As described before, the previously running applications’ work is lost in this manner since they are essentially killed by RM via the re-sync command on restart.
- Phase 2: Work-preserving RM restart
As of Hadoop 2.6.0, we further enhanced RM restart feature to address the problem to not kill any applications running on YARN cluster if RM restarts.
Beyond all the groundwork that has been done in Phase 1 to ensure the persistency of application state and reload that state on recovery, Phase 2 primarily focuses on re-constructing the entire running state of YARN cluster, the majority of which is the state of the central scheduler inside RM which keeps track of all containers’ life-cycle, applications’ headroom and resource requests, queues’ resource usage etc. In this way, RM doesn’t need to kill the AM and re-run the application from scratch as it is done in Phase 1. Applications can simply re-sync back with RM and resume from where it were left off.
RM recovers its runing state by taking advantage of the container statuses sent from all NMs. NM will not kill the containers when it re-syncs with the restarted RM. It continues managing the containers and send the container statuses across to RM when it re-registers. RM reconstructs the container instances and the associated applications’ scheduling status by absorbing these containers’ information. In the meantime, AM needs to re-send the outstanding resource requests to RM because RM may lose the unfulfilled requests when it shuts down. Application writers using AMRMClient library to communicate with RM do not need to worry about the part of AM re-sending resource requests to RM on re-sync, as it is automatically taken care by the library itself.
ResourceManager High Availability
Introduction
This guide provides an overview of High Availability of YARN’s ResourceManager, and details how to configure and use this feature. The ResourceManager (RM) is responsible for tracking the resources in a cluster, and scheduling applications (e.g., MapReduce jobs). Prior to Hadoop 2.4, the ResourceManager is the single point of failure in a YARN cluster. The High Availability feature adds redundancy in the form of an Active/Standby ResourceManager pair to remove this otherwise single point of failure.
Architecture
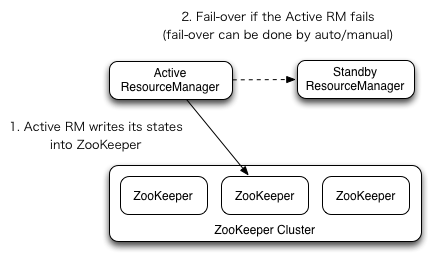
RM Failover
ResourceManager HA is realized through an Active/Standby architecture – at any point of time, one of the RMs is Active, and one or more RMs are in Standby mode waiting to take over should anything happen to the Active. The trigger to transition-to-active comes from either the admin (through CLI) or through the integrated failover-controller when automatic-failover is enabled.
Manual transitions and failover
When automatic failover is not enabled, admins have to manually transition one of the RMs to Active. To failover from one RM to the other, they are expected to first transition the Active-RM to Standby and transition a Standby-RM to Active. All this can be done using the “yarn rmadmin” CLI.
Automatic failover
The RMs have an option to embed the Zookeeper-based ActiveStandbyElector to decide which RM should be the Active. When the Active goes down or becomes unresponsive, another RM is automatically elected to be the Active which then takes over. Note that, there is no need to run a separate ZKFC daemon as is the case for HDFS because ActiveStandbyElector embedded in RMs acts as a failure detector and a leader elector instead of a separate ZKFC deamon.
Client, ApplicationMaster and NodeManager on RM failover
When there are multiple RMs, the configuration (yarn-site.xml) used by clients and nodes is expected to list all the RMs. Clients, ApplicationMasters (AMs) and NodeManagers (NMs) try connecting to the RMs in a round-robin fashion until they hit the Active RM. If the Active goes down, they resume the round-robin polling until they hit the “new” Active. This default retry logic is implemented as org.apache.hadoop.yarn.client.ConfiguredRMFailoverProxyProvider. You can override the logic by implementingorg.apache.hadoop.yarn.client.RMFailoverProxyProvider and setting the value of yarn.client.failover-proxy-provider to the class name.
Recovering prevous active-RM’s state
With the ResourceManger Restart enabled, the RM being promoted to an active state loads the RM internal state and continues to operate from where the previous active left off as much as possible depending on the RM restart feature. A new attempt is spawned for each managed application previously submitted to the RM. Applications can checkpoint periodically to avoid losing any work. The state-store must be visible from the both of Active/Standby RMs. Currently, there are two RMStateStore implementations for persistence – FileSystemRMStateStore and ZKRMStateStore. The ZKRMStateStore implicitly allows write access to a single RM at any point in time, and hence is the recommended store to use in an HA cluster. When using the ZKRMStateStore, there is no need for a separate fencing mechanism to address a potential split-brain situation where multiple RMs can potentially assume the Active role. When using the ZKRMStateStore, it is advisable to NOT set the “zookeeper.DigestAuthenticationProvider.superDigest” property on the Zookeeper cluster to ensure that the zookeeper admin does not have access to YARN application/user credential information.
Docker Container Executor
Overview
Docker combines an easy-to-use interface to Linux containers with easy-to-construct image files for those containers. In short, Docker launches very light weight virtual machines.
The Docker Container Executor (DCE) allows the YARN NodeManager to launch YARN containers into Docker containers. Users can specify the Docker images they want for their YARN containers. These containers provide a custom software environment in which the user’s code runs, isolated from the software environment of the NodeManager. These containers can include special libraries needed by the application, and they can have different versions of Perl, Python, and even Java than what is installed on the NodeManager. Indeed, these containers can run a different flavor of Linux than what is running on the NodeManager – although the YARN container must define all the environments and libraries needed to run the job, nothing will be shared with the NodeManager.
Docker for YARN provides both consistency (all YARN containers will have the same software environment) and isolation (no interference with whatever is installed on the physical machine).
Cluster Configuration
Docker Container Executor runs in non-secure mode of HDFS and YARN. It will not run in secure mode, and will exit if it detects secure mode.
The DockerContainerExecutor requires Docker daemon to be running on the NodeManagers, and the Docker client installed and able to start Docker containers. To prevent timeouts while starting jobs, the Docker images to be used by a job should already be downloaded in the NodeManagers. Here’s an example of how this can be done:
sudo docker pull sequenceiq/hadoop-docker:2.4.1
This should be done as part of the NodeManager startup.
The following properties must be set in yarn-site.xml:
<property>
<name>yarn.nodemanager.docker-container-executor.exec-name</name>
<value>/usr/bin/docker</value>
<description>
Name or path to the Docker client. This is a required parameter. If this is empty,
user must pass an image name as part of the job invocation(see below).
</description>
</property>
<property>
<name>yarn.nodemanager.container-executor.class</name>
<value>org.apache.hadoop.yarn.server.nodemanager.DockerContainerExecutor</value>
<description>
This is the container executor setting that ensures that all
jobs are started with the DockerContainerExecutor.
</description>
</property>
Administrators should be aware that DCE doesn’t currently provide user name-space isolation. This means, in particular, that software running as root in the YARN container will have root privileges in the underlying NodeManager. Put differently, DCE currently provides no better security guarantees than YARN’s Default Container Executor. In fact, DockerContainerExecutor will exit if it detects secure yarn.
Tips for connecting to a secure docker repository
By default, docker images are pulled from the docker public repository. The format of a docker image url is: username/image_name. For example, sequenceiq/hadoop-docker:2.4.1 is an image in docker public repository that contains java and hadoop.
If you want your own private repository, you provide the repository url instead of your username. Therefore, the image url becomes: private_repo_url/image_name. For example, if your repository is on localhost:8080, your images would be like: localhost:8080/hadoop-docker
To connect to a secure docker repository, you can use the following invocation:
docker login [OPTIONS] [SERVER]
Register or log in to a Docker registry server, if no server is specified
"https://index.docker.io/v1/" is the default.
-e, --email="" Email
-p, --password="" Password
-u, --username="" Username
If you want to login to a self-hosted registry you can specify this by adding the server name.
docker login <private_repo_url>
This needs to be run as part of the NodeManager startup, or as a cron job if the login session expires periodically. You can login to multiple docker repositories from the same NodeManager, but all your users will have access to all your repositories, as at present the DockerContainerExecutor does not support per-job docker login.
Job Configuration
Currently you cannot configure any of the Docker settings with the job configuration. You can provide Mapper, Reducer, and ApplicationMaster environment overrides for the docker images, using the following 3 JVM properties respectively(only for MR jobs):
- mapreduce.map.env: You can override the mapper’s image by passing yarn.nodemanager.docker-container-executor.image-name=your_image_name to this JVM property.
- mapreduce.reduce.env: You can override the reducer’s image by passing yarn.nodemanager.docker-container-executor.image-name=your_image_name to this JVM property.
- yarn.app.mapreduce.am.env: You can override the ApplicationMaster’s image by passing yarn.nodemanager.docker-container-executor.image-name=your_image_name to this JVM property.
Docker Image Requirements
The Docker Images used for YARN containers must meet the following requirements:
The distro and version of Linux in your Docker Image can be quite different from that of your NodeManager. (Docker does have a few limitations in this regard, but you’re not likely to hit them.) However, if you’re using the MapReduce framework, then your image will need to be configured for running Hadoop. Java must be installed in the container, and the following environment variables must be defined in the image: JAVA_HOME, HADOOP_COMMON_PATH, HADOOP_HDFS_HOME, HADOOP_MAPRED_HOME, HADOOP_YARN_HOME, and HADOOP_CONF_DIR
Working example of yarn launched docker containers
The following example shows how to run teragen using DockerContainerExecutor.
Step 1. First ensure that YARN is properly configured with DockerContainerExecutor(see above).
<property>
<name>yarn.nodemanager.docker-container-executor.exec-name</name>
<value>docker -H=tcp://0.0.0.0:4243</value>
<description>
Name or path to the Docker client. The tcp socket must be
where docker daemon is listening.
</description>
</property>
<property>
<name>yarn.nodemanager.container-executor.class</name>
<value>org.apache.hadoop.yarn.server.nodemanager.DockerContainerExecutor</value>
<description>
This is the container executor setting that ensures that all
jobs are started with the DockerContainerExecutor.
</description>
</property>
Step 2. Pick a custom Docker image if you want. In this example, we’ll use sequenceiq/hadoop-docker:2.4.1 from the docker hub repository. It has jdk, hadoop, and all the previously mentioned environment variables configured.
Step 3. Run.
hadoop jar $HADOOP_PREFIX/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.2.jar \
teragen \
-Dmapreduce.map.env="yarn.nodemanager.docker-container-executor.image-name=sequenceiq/hadoop-docker:2.4.1" \
-Dyarn.app.mapreduce.am.env="yarn.nodemanager.docker-container-executor.image-name=sequenceiq/hadoop-docker:2.4.1" \
1000 \
teragen_out_dir
Once it succeeds, you can check the yarn debug logs to verify that docker indeed has launched containers.