在分布式缓存和分布式存储系统上经常用到一致性哈希算法,今天特地来学习一下。
一致哈希 是一种特殊的哈希算法。在使用一致哈希算法后,哈希表槽位数(大小)的改变平均只需要对 个关键字重新映射,其中
个关键字重新映射,其中 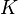 是关键字的数量,
是关键字的数量, 是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
历史
一致哈希由MIT的Karger及其合作者提出,现在这一思想已经扩展到其它领域。在这篇1997年发表的学术论文中介绍了“一致哈希”如何应用于用户易变的分布式Web服务中[1]。哈希表中的每一个代表分布式系统中一个节点,在系统添加或删除节点只需要移动项。
一致哈希也可用于实现健壮缓存来减少大型Web应用中系统部分失效带来的负面影响。
一致哈希的概念还被应用于分布式散列表(DHT)的设计。DHT使用一致哈希来划分分布式系统的节点。所有关键字都可以通过一个连接所有节点的覆盖网络高效地定位到某个节点。
需求
在使用n台缓存服务器时,一种常用的负载均衡方式是,对资源o的请求使用 来映射到某一台缓存服务器。当增加或减少一台缓存服务器时这种方式可能会改变所有资源对应的hash值,也就是所有的缓存都失效了,这会使得缓存服务器大量集中地向原始内容服务器更新缓存。因些需要一致哈希算法来避免这样的问题。 一致哈希尽可能使同一个资源映射到同一台缓存服务器。这种方式要求增加一台缓存服务器时,新的服务器尽量分担存储其他所有服务器的缓存资源。减少一台缓存服务器时,其他所有服务器也可以尽量分担存储它的缓存资源。 一致哈希算法的主要思想是将每个缓存服务器与一个或多个哈希值域区间关联起来,其中区间边界通过计算缓存服务器对应的哈希值来决定。(定义区间的哈希函数不一定和计算缓存服务器哈希值的函数相同,但是两个函数的返回值的范围需要匹配。)如果一个缓存服务器被移除,则它会从对应的区间会被并入到邻近的区间,其他的缓存服务器不需要任何改变。
来映射到某一台缓存服务器。当增加或减少一台缓存服务器时这种方式可能会改变所有资源对应的hash值,也就是所有的缓存都失效了,这会使得缓存服务器大量集中地向原始内容服务器更新缓存。因些需要一致哈希算法来避免这样的问题。 一致哈希尽可能使同一个资源映射到同一台缓存服务器。这种方式要求增加一台缓存服务器时,新的服务器尽量分担存储其他所有服务器的缓存资源。减少一台缓存服务器时,其他所有服务器也可以尽量分担存储它的缓存资源。 一致哈希算法的主要思想是将每个缓存服务器与一个或多个哈希值域区间关联起来,其中区间边界通过计算缓存服务器对应的哈希值来决定。(定义区间的哈希函数不一定和计算缓存服务器哈希值的函数相同,但是两个函数的返回值的范围需要匹配。)如果一个缓存服务器被移除,则它会从对应的区间会被并入到邻近的区间,其他的缓存服务器不需要任何改变。
实现
一致哈希将每个对象映射到圆环边上的一个点,系统再将可用的节点机器映射到圆环的不同位置。查找某个对象对应的机器时,需要用一致哈希算法计算得到对象对应圆环边上位置,沿着圆环边上查找直到遇到某个节点机器,这台机器即为对象应该保存的位置。 当删除一台节点机器时,这台机器上保存的所有对象都要移动到下一台机器。添加一台机器到圆环边上某个点时,这个点的下一台机器需要将这个节点前对应的对象移动到新机器上。 更改对象在节点机器上的分布可以通过调整节点机器的位置来实现。





template <class Node, class Data, class Hash = HASH_NAMESPACE::hash<const char*> > class HashRing { public: typedef std::map<size_t, Node> NodeMap; HashRing(unsigned int replicas) : replicas_(replicas), hash_(HASH_NAMESPACE::hash<const char*>()) { } HashRing(unsigned int replicas, const Hash& hash) : replicas_(replicas), hash_(hash) { } size_t AddNode(const Node& node); void RemoveNode(const Node& node); const Node& GetNode(const Data& data) const; private: NodeMap ring_; const unsigned int replicas_; Hash hash_; }; template <class Node, class Data, class Hash> size_t HashRing<Node, Data, Hash>::AddNode(const Node& node) { size_t hash; std::string nodestr = Stringify(node); for (unsigned int r = 0; r < replicas_; r++) { hash = hash_((nodestr + Stringify(r)).c_str()); ring_[hash] = node; } return hash; } template <class Node, class Data, class Hash> void HashRing<Node, Data, Hash>::RemoveNode(const Node& node) { std::string nodestr = Stringify(node); for (unsigned int r = 0; r < replicas_; r++) { size_t hash = hash_((nodestr + Stringify(r)).c_str()); ring_.erase(hash); } } template <class Node, class Data, class Hash> const Node& HashRing<Node, Data, Hash>::GetNode(const Data& data) const { if (ring_.empty()) { throw EmptyRingException(); } size_t hash = hash_(Stringify(data).c_str()); typename NodeMap::const_iterator it; // Look for the first node >= hash it = ring_.lower_bound(hash); if (it == ring_.end()) { // Wrapped around; get the first node it = ring_.begin(); } return it->second; }
特性
David Karger及其合作者列出了使得一致哈希在互联网分布式缓存中非常有用的几个特性:
- 冗余少
- 负载均衡
- 过渡平滑
- 存储均衡
- 关键词单调
问题
上边描述的一致性Hash算法有个潜在的问题是:
将节点hash后会不均匀地分布在环上,这样大量key在寻找节点时,会存在key命中各个节点的概率差别较大,无法实现有效的负载均衡。可以使用虚拟节点的思想,为每个物理节点(服务器)在圆上分配100~200个点。这样就能抑制分布不均匀,最大限度地减小服务器增减时的缓存重新分布。用户数据映射在虚拟节点上,就表示用户数据真正存储位置是在该虚拟节点代表的实际物理服务器上。