Channel types
channel 类型通过发送和接受特定类型的值,为并行执行函数提供一种通信机制。 channel是先进先出类型的管道,默认情况下,在另一端准备好之前,发送和接收都会阻塞。这使得 goroutine 可以在没有明确的锁或竞态变量的情况下进行同步。
ChannelType = ( "chan" | "chan" "<-" | "<-" "chan" )
箭头是管道的方向,发送或接收,如果没有指定方向,管道是双向的。一个channel可能受限于只能发送或接收。
chan T // can be used to send and receive values of type T
chan<- float64 // can only be used to send float64s
<-chan int // can only be used to receive ints
The <- operator associates with the leftmost chan possible:
chan<- chan int // same as chan<- (chan int)
chan<- <-chan int // same as chan<- (<-chan int)
<-chan <-chan int // same as <-chan (<-chan int)
chan (<-chan int)
channel可以使用内置的make函数创建并初始化,make参数指定类型和可选的容量。未初始化的channel值为nil。
make(chan int, 100)
容量,指定channel的buffer大小,元素个数。如果容量未指定或者为0,channel是没有buffer的,只有发送和接收都准备好的时候,通信成功。否则,channel是可缓冲的,通信不阻塞,只要空间不为空(接受者),或者空间不满(发送者)。但是值为nil的channel会一直阻塞。
channel可以使用内置函数close关闭。 接受者可以使用多值赋值的方法判断channel是否关闭。当channel关闭时,ok值为false。
x, ok = <-ch
x, ok := <-ch
var x, ok = <-ch
注意
- 给一个 nil channel 发送数据,造成永远阻塞
- 从一个 nil channel 接收数据,造成永远阻塞
- 给一个已经关闭的 channel 发送数据,引起 panic
- 从一个已经关闭的 channel 接收数据,立即返回一个零值
给一个 nil channel 发送数据,造成永远阻塞
这第一个例子对于新来者是有点小惊奇的,它给一个 nil channel 发送数据,造成永远阻塞。
以下这个程序将在第5行造成死锁,因为未初始化的 channel 是 nil 的,其值是零
package main
func main() {
var c chan string
c <- "let's get started" // deadlock
}
从一个 nil channel 接收数据,造成永远阻塞
类似的,从一个 nil channel 接收数据,会造成接受者永远阻塞。
package main
import "fmt"
func main() {
var c chan string
fmt.Println(<-c) // deadlock
}
为什么会发生这样的情况?下面是一个可能的解释
- channel 的 buffer 的大小不是类型声明的一部分,因此它必须是 channel 的值的一部分
- 如果 channel 未被初始化,它的 buffer 的大小将是0
- 如果 channel 的 buffer 大小是0,那么它将没有 buffer
- 如果 channel 没有 buffer,一个发送将会被阻塞,直到另外一个 goroutine 为接收做好了准备
- 如果 channel 是 nil 的,并且接收者和发送者没有任何交互,他们都会阻塞然后在各自的 channel 中等待以及不再被解除阻塞状态
给一个已经关闭的 channel 发送数据,引起 panic
以下程序将有可能 panic,因为在它的兄弟姐妹有时间完成发送他们的值之前,这第一个 goroutine 在达到10的时候将关闭 channel。
package main
import "fmt"
func main() {
var c = make(chan int, 100)
for i := 0; i < 10; i++ {
go func() {
for j := 0; j < 10; j++ {
c <- j
}
close(c)
}()
}
for i := range c {
fmt.Println(i)
}
}
因此为什么没有一个 close() 版本能让你检测 channel 是否关闭?
if !isClosed(c) {
// c isn't closed, send the value
c <- v
}
但是这个函数有一个内在的竞争,某个人可能在我们检查完 isClosed(c) 之后,但是代码获取 c <- v 之前关闭这个 channel。处理这个问题的方法参考Go Concurrency Patterns: Pipelines and cancellation 。
从一个已经关闭的 channel 接收数据,立即返回一个零值
这最后一个示例与前一个是相反的,一旦一个 channel 被关闭,它的所有的值都会从 buffer 中流失,channel 将立即返回0值。
package main
import "fmt"
func main() {
c := make(chan int, 3)
c <- 1
c <- 2
c <- 3
close(c)
for i := 0; i < 4; i++ {
fmt.Printf("%d ", <-c) // prints 1 2 3 0
}
}
针对这个问题的正确的解决办法是使用 range 循环处理:
for v := range c {
// do something with v
}
for v, ok := <- c; ok ; v, ok = <- c {
// do something with v
}
这两个语句在函数中是相等的,展示 range 是做什么。
参考文献:
[1]. Go 指南
[2]. Go – Channel 原理
[3]. The Go Programming Language Specification




 个关键字重新映射,其中
个关键字重新映射,其中 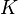 是关键字的数量,
是关键字的数量, 是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。
是槽位数量。然而在传统的哈希表中,添加或删除一个槽位的几乎需要对所有关键字进行重新映射。 来映射到某一台缓存服务器。当增加或减少一台缓存服务器时这种方式可能会改变所有资源对应的hash值,也就是所有的缓存都失效了,这会使得缓存服务器大量集中地向原始内容服务器更新缓存。因些需要一致哈希算法来避免这样的问题。 一致哈希尽可能使同一个资源映射到同一台缓存服务器。这种方式要求增加一台缓存服务器时,新的服务器尽量分担存储其他所有服务器的缓存资源。减少一台缓存服务器时,其他所有服务器也可以尽量分担存储它的缓存资源。 一致哈希算法的主要思想是将每个缓存服务器与一个或多个哈希值域区间关联起来,其中区间边界通过计算缓存服务器对应的哈希值来决定。(定义区间的哈希函数不一定和计算缓存服务器哈希值的函数相同,但是两个函数的返回值的范围需要匹配。)如果一个缓存服务器被移除,则它会从对应的区间会被并入到邻近的区间,其他的缓存服务器不需要任何改变。
来映射到某一台缓存服务器。当增加或减少一台缓存服务器时这种方式可能会改变所有资源对应的hash值,也就是所有的缓存都失效了,这会使得缓存服务器大量集中地向原始内容服务器更新缓存。因些需要一致哈希算法来避免这样的问题。 一致哈希尽可能使同一个资源映射到同一台缓存服务器。这种方式要求增加一台缓存服务器时,新的服务器尽量分担存储其他所有服务器的缓存资源。减少一台缓存服务器时,其他所有服务器也可以尽量分担存储它的缓存资源。 一致哈希算法的主要思想是将每个缓存服务器与一个或多个哈希值域区间关联起来,其中区间边界通过计算缓存服务器对应的哈希值来决定。(定义区间的哈希函数不一定和计算缓存服务器哈希值的函数相同,但是两个函数的返回值的范围需要匹配。)如果一个缓存服务器被移除,则它会从对应的区间会被并入到邻近的区间,其他的缓存服务器不需要任何改变。



